
这是 TelePath 的开发记录
随着 TelePath 开发的持续推进,系统已经越来越复杂,中途补一个开发记录似乎越来越重要了起来,所以也就有了此文,当然主要里面的内容是写给我自己看的,所以有哪里不懂那只能怪我文笔不行只会写自言自语的文字了真是抱歉,如果你对 Buffering & Cahce 之类的研究感兴趣的话也欢迎一起看看和讨论哦。
仓库地址是:this
具体是做什么,其实在 about 里面说的已经很清楚了:
About
TelePath: A C++17 SDK for observable buffer pools & page cache on modern storage. Unlike black-box engines, it treats Cloud-Native Observability as a first-class citizen, offering a transparent, high-throughput framework for research and systems development.
目前是 C++ 但以后也想支持 Rust 捏,纯画饼。
封面小女孩是谁?其实是一首歌曲心灵感应(テレパシ, Telepathy),但是很有意思,当时新建的时候,给 Repo 起个名字吧,突然随机播放到这首歌,然后结合之前考虑的 Telemetry 特点,名字很自然的就成为了 TelePath,毕竟可观测性是灵魂特点,不可失去。
为什么考虑可观测性?其实现实来看,社区角度和个人角度都是非常自然的特点的落地。
- 社区角度,开源社区确实是缺少一个以 Observability 为卖点的数据库或者说缓冲池,页缓存,工业级别底层内核都是极其注重效率的,可观测性往往是可以被牺牲的事后补丁。好了稀缺性有了,可以做。
- 个人角度,要知道这个项目和我的毕设有关,系统的代码那么多,动辄上万,内核代码什么直观的效果都看不到最后哪里打得过那些做提示词,做微调的毕设项目是吧,系统搬砖这一行,遇到不懂行的老师的话就苦了,最后什么都看不到,苦苦延毕,失去所有的 offer 再读一年,我的人生就彻底结束了。所以要让不懂行的老师也无处可攻击。
想法是很自然地获得的,于是在歌曲下新建文件夹了(新建仓库)。

TelePath 是什么
这一部分都严肃地正式来说说:
TelePath 是一个高并发、可观测的缓冲池和页缓存引擎。
很多教学型实现更强调功能闭环,但对并发语义、异步写回以及运行时可观察性考虑得不够。如果后面想做性能分析、替换策略比较,或者定位系统瓶颈,往往只能临时加日志,这样既侵入,也不利于做系统实验。所以我从一开始就想把它做成一个“数据面和观测面解耦”的实验平台。
具体实现上,核心模块是 BufferManager、BufferHandle 和 BufferDescriptor。BufferHandle 用 RAII 管理页面访问生命周期,BufferManager 负责缓存生命周期、缺页装载、页面驱逐和刷盘调度。在并发上,我做了分条页表锁和同页并发缺页协调,避免多个线程重复读同一页。在 I/O 路径上,我抽象了 DiskBackend,同时支持 POSIX fallback 和 io_uring 路径,并实现了集中式分发机制、前后台 flush 队列、自适应清理。观测面则通过 TelemetrySink 和快路径计数器记录命中、缺页、驱逐、刷盘等事件,用来支持 benchmark、回归测试和后续可视化分析。
解决什么问题
TelePath 要解决的是更具体的三个系统问题。
- 第一,传统 Buffer Pool 的核心路径通常把页表、替换器、磁盘 I/O 和状态管理强耦合在一起,功能上能跑通,但一旦进入高并发场景,页表锁竞争、重复缺页、刷盘路径阻塞这些问题就会很快暴露出来。
- 第二,很多实现默认同步 I/O 或粗粒度后台写回,难以支持对异步刷盘、批量提交和并发驱逐策略的系统性实验。
- 第三,也是 TelePath 最在意的一点,缓冲池通常是黑盒的,命中率、缺页、驱逐、写回延迟这些信息很难低成本地持续采集,后续做 benchmark、回归分析或可视化时会很被动。
所以 TelePath 想做的事情,本质上是把“缓存管理”“异步存储访问”和“运行时观测”放进同一个实验框架里,让它既能作为一个高并发 Buffer Pool 原型,也能作为后续研究替换策略、I/O 调度和系统可观测性的基础平台。
系统边界在哪里
TelePath 的边界首先很明确:它是一个进程内的 Buffer Pool / Page Cache Engine,而不是完整的数据库系统。它负责管理页在内存中的驻留状态,处理页的装载、pin/unpin、驱逐、脏页刷回,以及与底层磁盘后端之间的异步 I/O 协调;同时,它还负责暴露运行时观测接口,记录命中、缺页、驱逐、刷盘等关键事件。
但 TelePath 不负责更上层的查询执行、事务管理、恢复协议、日志系统或 SQL 语义,也不试图替代操作系统内核页缓存。换句话说,它关注的是一个高并发页缓存引擎本身如何工作,而不是一个完整数据库如何工作。底层上,它依赖 DiskBackend 提供块设备或文件级 I/O 抽象;上层上,它假定调用者已经决定了 page_id 的含义、页面格式以及访问时机。这样做的目的,是把实验范围控制在缓存管理、并发控制、异步 I/O 和观测机制这几个核心问题上,避免系统边界无限膨胀。
当前实现到什么程度
从当前代码结构来看,TelePath 已经具备了核心路径的原型系统。数据面上,已经形成了以 BufferManager、BufferHandle 和 BufferDescriptor 为核心的对象模型,能够覆盖页面访问生命周期、缺页装载、并发下的页状态协调,以及基本的驱逐与刷盘流程。并发控制方面,已经开始从教学型实现常见的全局串行路径中脱离出来,引入分条页表锁和同页缺页协调,避免明显的热点竞争和重复 I/O。
I/O 路径上,目前已经抽象出 DiskBackend,并同时考虑了 POSIX fallback 和 io_uring 两条路径;同时,围绕刷盘调度已经出现了集中式分发、前后台 flush 队列和自适应清理这些机制,说明 TelePath 的重点已经不只是“把页写回去”,而是在尝试建立一条更接近真实系统的异步写回路径。观测面上,也已经不是简单打印日志,而是通过 TelemetrySink 和快路径计数器,把命中、缺页、驱逐、刷盘等事件纳入统一观测接口。
不过它目前仍然更接近一个持续演进中的系统原型,而不是已经完全收敛的基础设施库。也就是说,核心模块和关键路径已经成型,但替换策略、观测链路、I/O 调度细节以及接口稳定性,仍然处在可以继续重构和验证的阶段。
架构
目前的架构如下,我们先自顶向下宏观来看看这是在干啥的,这个架构是会不断持续更新的,但核心不变:
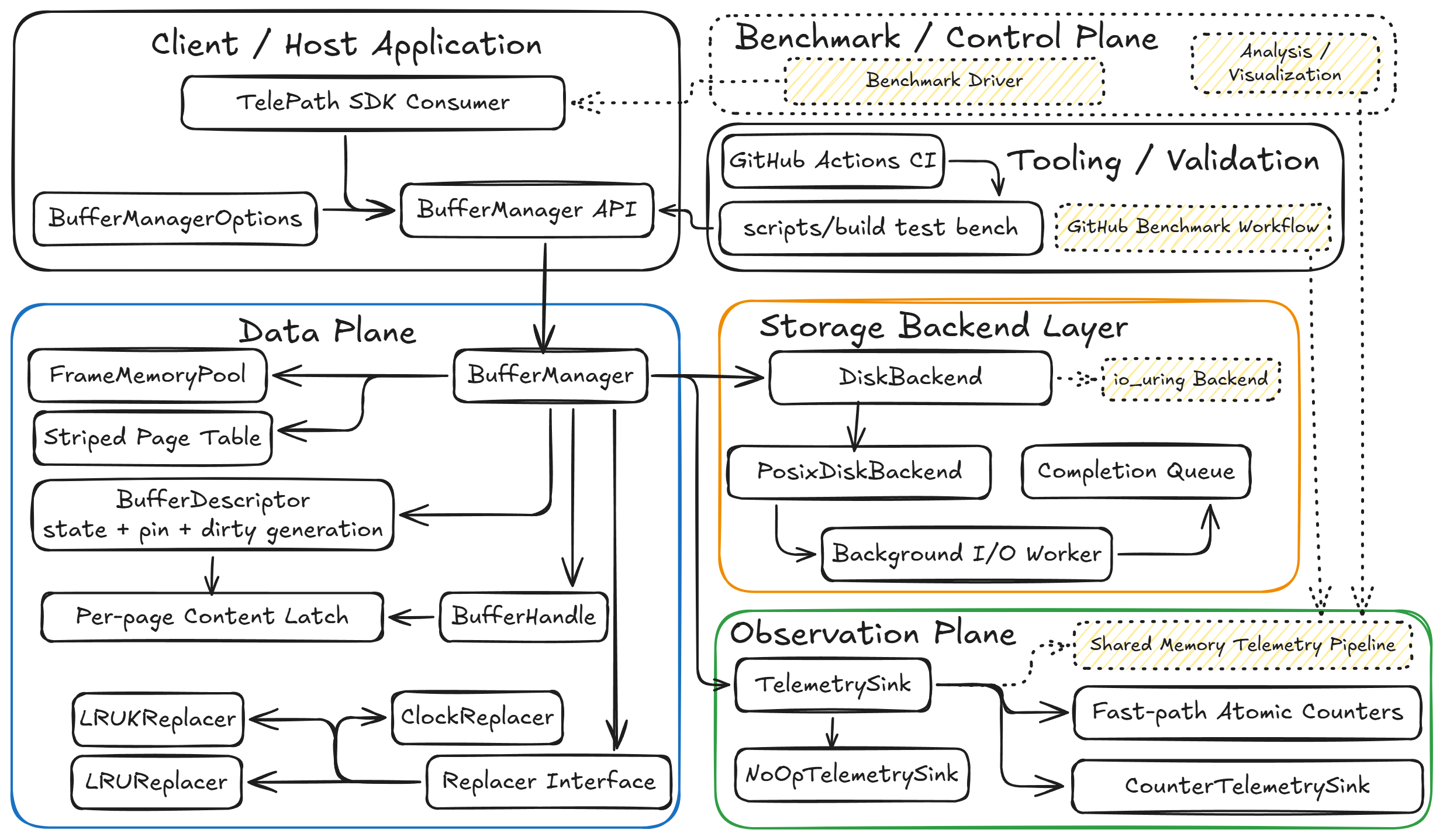
缓冲池或者说页缓存也算是臭名昭著的超级大耦合系统了,所以现在看,东西这么多,非常可怕,不怕,我们只看四个框框,那其实非常易于理解。
- Public API Surface: 直接于上层的调用者交互的接口。
- Core Cahce Engine: 这里就是传统的 Buffer Manager 的核心逻辑了,数据层,所有系统搬砖的精华都在里面。
- Storage Backend Layer: 直接和磁盘交互的最底层。
- In-process Observation: 本项目得以存活的立身之本,观测层。
具体的内容我们后面再看。
模块各自职责
…
模块之间的数据流 / 控制流
…
核心对象模型
这里介绍一些核心的对象模型,以及它们各自拥有谁、引用谁、生命周期是什么。
Page
也许有部分看到这里的读者还不懂 Page 和 Frame 之间都是些啥,具体来说,buffering 就相当于一个连接磁盘和内存的 cache(cache 是连接内存和 CPU 的嘛),大家对 cache 很熟悉的话其实 buffering 也应该很好理解了,Frame 就是在内存申请的各个页框,负责装载需要的 Page,Page 则是从磁盘拿出来,装到内存的 Frame 中,然后给各个线程操作,必要的时候再写回去。
但我们的实现中没有 Page 类,Page 是逻辑上的磁盘页,逻辑页的身份由 BufferTag(file_id, block_id) 表示。通过将逻辑页和物理实体拆分开,BufferManager 更容易做页表映射、换入换出、驱逐恢复和并发状态检查,而不用维护一个重量级 Page 对象到处传。
当然为什么两个 uint 就能知道这个 Page 是哪里的呢?因为 TelePath 的磁盘后端约定了这两个字段的含义,能将页映射为文件路径于文件内偏移,翻译成了真实 I/O 地址。这个具体我们后面磁盘后端再说。
当它驻留内存时,会映射到某个 frame_id 对应的 Frame 上。也就是说,逻辑页身份和承载它的内存槽位是分离的。这使得对象边界更清楚,不用搬动一个复杂对象传来传去。
Frame
我们的实现中没有 Frame 类,但 Frame 也是一个物理槽位,内存的框,那我们如何标识它:
FrameMemoryPool: 这就是 Frame 们所在的内存块中,具体来说是它的一个私有对象data_,内存多大呢,page_size这么大,具体来说,内存范围是连续内存data_中的这个字节区域:$\displaystyle [\text{frame\_id} \cdot \text{page\_size},\ (\text{frame\_id}+1)\cdot \text{page\_size})$frame_id: 给每个 Frame 开一个 ID 就可以。BufferDescriptor: 这是什么?这是每个 Frame 都有的一个描述符,和BufferHandle不一样,无论有没有页入住都存在,能表示框的不同状态。
有了它们,Frame 就能写入 buffer pool 中,作为物理槽位为页提供住所。
BufferTag
这是逻辑页的唯一键:file_id + block_id,本质上就是一个二元组:(文件编号, 文件内页号),只是一个逻辑页标识符。
struct BufferTag {
FileId file_id{0};
BlockId block_id{0};
bool operator==(const BufferTag &other) const;
bool operator!=(const BufferTag &other) const;
};
前面提到过,这两个整数就能定位一个磁盘页,是由磁盘后端约定的。具体可以在磁盘后端的时候看,这里简单提一下。例如看 POSIX backend:return root_path_ + "/file_" + std::to_string(file_id) + ".tp";
也就是说,我们假设一个页的 BufferTag 是 {1, 2},file_id 首先就是 1,然后对应文件就是 file_1.tp。
然后 block_id 被映射成这个文件里的页偏移:const off_t offset = static_cast<off_t>(tag.block_id * page_size_);
也就是说,block_id 是 2,page_size = 4096 时,偏移就是 2 * 4096 = 8192,即对应到 POSIX backend 上,就是读写 file_1.tp 的偏移 8192。
以上就是如何通过 BufferTag 找到一个其磁盘的位置,可见 BufferTag 只能标识要找哪个逻辑页,但它本身并不知道这个页当前是否已经在内存中。那如何通过 BufferTag 找到对应的 Frame 呢?到 Frame 的定位是由 BufferManager 内部维护的页表完成的。其实本质上就是一个分条带锁的哈希表。具体逻辑我们后面再说,这是一个稍微复杂的状态机。
BufferDescriptor
前面提到,这是每个 Frame 都有的一个描述符。
struct alignas(kCacheLineSize) BufferDescriptor {
// Per-frame coordination used by the data plane.
mutable std::condition_variable io_cv;
mutable std::mutex latch;
mutable std::shared_mutex content_latch;
// Frame identity and ownership.
BufferTag tag{};
FrameId frame_id{kInvalidFrameId};
// Resident page metadata.
uint32_t pin_count{0};
uint64_t dirty_generation{0};
bool is_dirty{false};
bool is_valid{false};
// I/O and flush lifecycle flags.
bool io_in_flight{false};
bool flush_queued{false};
bool flush_in_flight{false};
Status last_io_status{};
Status last_flush_status{};
// Residency state machine.
BufferFrameState state{BufferFrameState::kFree};
};
我们可以看到里面有很多 bool,用于记录状态机、pin_count、dirty 状态、I/O 状态和内容锁。因为它只是一个描述符,所以不存 page bytes,只存这块 frame 当前装的是谁、现在处于什么状态。
迁移状态,即 enum class BufferFrameState,里面存有 kFree、kLoading、kResident 表示现在的框的情况。
这里面有一个非常关键的 alignas(kCacheLineSize),读者可以猜一猜为什么需要,其避免了一个什么问题。
BufferHandle
BufferHandle 则是一个非常重要的页句柄,其维护着页的生命周期,使得逻辑页的生命周期与其作用域绑定起来。
class BufferHandle {
public:
// Creates an empty handle that does not reference any frame.
BufferHandle() = default;
// Creates a pinned handle for a resident frame.
BufferHandle(
BufferManager *manager,
FrameId frame_id,
const BufferTag &tag,
std::byte *data,
std::size_t size);
BufferHandle(const BufferHandle &) = delete;
BufferHandle &operator=(const BufferHandle &) = delete;
BufferHandle(BufferHandle &&other) noexcept;
BufferHandle &operator=(BufferHandle &&other) noexcept;
~BufferHandle();
auto tag() const -> const BufferTag & { return tag_; }
auto frame_id() const -> FrameId { return frame_id_; }
auto size() const -> std::size_t { return size_; }
// Returns read-only access to the page contents. The handle acquires and
// holds a shared content latch on first access.
auto data() const -> const std::byte *;
// Returns writable access to the page contents. The handle upgrades to an
// exclusive content latch and holds it until Reset/destruction.
auto mutable_data() -> std::byte *;
bool writable() const { return data_ != nullptr; }
bool valid() const { return manager_ != nullptr; }
// Releases any held content latch and unpins the underlying frame.
void Reset();
private:
friend class BufferManager;
BufferManager *manager_{nullptr};
FrameId frame_id_{kInvalidFrameId};
BufferTag tag_{};
std::byte *data_{nullptr};
std::size_t size_{0};
mutable std::shared_lock<std::shared_mutex> read_lock_;
std::unique_lock<std::shared_mutex> write_lock_;
};
先直接看 private 这几个量,我们可以看到其构造时只保存了这五个上下文成员,然后自己持有一把读锁和一把写锁。由于其与生命周期息息相关,它是 move-only 的 RAII 访问句柄,不可拷贝,那它负责什么?它作为 Page 的访问票据在 Page 几乎一切的主流程中穿插,负责了 Page 被访问的上下文,在首次读写时获取内容锁,并在析构或 Reset() 时释放锁并对 frame 执行 unpin。
BufferManager
BufferManager 是整个 buffer pool 的运行时管理者,也是全项目最核心的对象。
class BufferManager {
public:
// Builds a buffer manager from explicit options. Initialization failures are
// surfaced through subsequent API calls as Status values.
BufferManager(
const BufferManagerOptions &options,
std::unique_ptr<DiskBackend> disk_backend,
std::unique_ptr<Replacer> replacer,
std::shared_ptr<TelemetrySink> telemetry_sink);
// Convenience overload for callers that only want pool/page sizing.
BufferManager(
std::size_t pool_size, std::size_t page_size,
std::unique_ptr<DiskBackend> disk_backend,
std::unique_ptr<Replacer> replacer,
std::shared_ptr<TelemetrySink> telemetry_sink);
~BufferManager();
// Pins the requested page in memory and returns a scoped handle to it. The
// page may be loaded from disk or served from the resident cache.
Result<BufferHandle> ReadBuffer(FileId file_id, BlockId block_id);
// Explicitly releases a handle before it goes out of scope.
Status ReleaseBuffer(BufferHandle &&handle);
// Marks the page referenced by the handle as dirty so that it will be
// written back before eviction or during an explicit flush.
Status MarkBufferDirty(const BufferHandle &handle);
// Flushes the page referenced by the handle to the backing store.
Status FlushBuffer(const BufferHandle &handle);
// Flushes every currently resident dirty page.
Status FlushAll();
// Returns a point-in-time view of frame metadata for observability and debug
// tooling. This does not expose direct page memory access.
BufferPoolSnapshot ExportSnapshot() const;
std::size_t pool_size() const { return pool_size_; }
std::size_t page_size() const { return page_size_; }
// Returns the resolved runtime options, including derived defaults.
const BufferManagerOptions &options() const { return options_; }
private:
friend class BufferHandle;
...
std::size_t pool_size_{0};
std::size_t page_size_{0};
BufferManagerOptions options_{};
std::unique_ptr<DiskBackend> disk_backend_;
std::unique_ptr<Replacer> replacer_;
std::unique_ptr<BufferManagerObserver> observer_;
Status init_status_{Status::Ok()};
std::unique_ptr<FrameMemoryPool> frame_pool_;
std::unique_ptr<BufferManagerMissCoordinator> miss_coordinator_;
std::unique_ptr<BufferManagerCompletionDispatcher> completion_dispatcher_;
std::unique_ptr<BufferManagerFlushScheduler> flush_scheduler_;
std::unique_ptr<BufferManagerCleanerController> cleaner_controller_;
std::unique_ptr<BufferManagerPageTable> page_table_;
std::vector<BufferDescriptor> descriptors_;
std::mutex free_list_latch_;
std::atomic<std::size_t> dirty_page_count_{0};
std::vector<FrameId> free_list_;
};
BufferManager 是整个对象模型的根拥有者和协调中心,它拥有的关键对象:
frame_pool_:底层 frame 字节内存descriptors_:每个 frame 的控制块page_table_:BufferTag->FrameIdmiss_coordinator_:同页并发 miss 协调completion_dispatcher_:异步 I/O completion 分发flush_scheduler_:刷盘任务调度cleaner_controller_:后台 cleanerdisk_backend_:实际磁盘后端replacer_:淘汰策略observer_:观测埋点
不看中间和底层的复杂交互逻辑,纯粹从顶层来看,其职责语义还是非常清晰的,职责上它至少负责这几件事:
ReadBuffer入口:hit / miss / load / join misspin/unpin生命周期dirty标记与flush路径eviction与victim恢复- 调用 replacer、磁盘后端、页表、cleaner、completion 分发
- 对外暴露统一 API
Replacer
Replacer 应该大家就都很熟悉了,负责了对页框的驱逐工作,它决定该淘汰谁。
class Replacer {
public:
virtual ~Replacer() = default;
// Records an access to the given frame so the policy can update its
// recency/history metadata.
virtual void RecordAccess(FrameId frame_id) = 0;
// Marks whether the given frame may currently be selected as an eviction
// victim. Pinned frames are typically non-evictable.
virtual void SetEvictable(FrameId frame_id, bool evictable) = 0;
// Selects one evictable frame as the next victim. Returns false when no
// evictable frame is available.
virtual bool Victim(FrameId *frame_id) = 0;
// Removes a frame from the replacer state if it is currently tracked.
virtual void Remove(FrameId frame_id) = 0;
// Returns the number of frames that are both tracked and evictable.
virtual auto Size() const -> std::size_t = 0;
};
为什么是虚的?因为我们的 Replacer 可插拔,实现了 Clock,LRU,LRU-K,2-Queue(其实是一种不严格但常数速度的 LRU-K)。
Replacer 采用虚接口主要是为了支持策略可插拔。理论上虚调用会带来一次间接调用开销,但相对于页表查找、锁竞争和 I/O 等成本,这部分通常不是主导瓶颈,因此这种抽象在当前阶段是合理的。
可见,Replacer 不拥有页内容,也不拥有 frame 本身。只是一个策略调度器,维护哪些 resident frame 可以被淘汰,以及优先淘汰谁的策略。它直接工作的交互对象是 FrameId,不是 BufferTag,也不是字节内容。
接口语义:
RecordAccess(frame_id):记录访问历史SetEvictable(frame_id, bool):设置当前是否可驱逐Victim(&frame_id):选一个 victimRemove(frame_id):从策略状态中移除Size():当前可驱逐集合大小
Replacer 只回答该淘汰谁,只有这一个任务,但也是整个 Buffer 里最有头脑,优化上限最高的组件。
其他?
除了这些稳定存在的核心对象外,TelePath 在异步 I/O 路径中还有 DiskRequest、DiskCompletion、FlushTask 等瞬时工作对象。它们主要服务于存储后端与完成事件分发,不属于 buffer pool 的核心对象模型,因此放到后面的磁盘后端章节再展开。
请求完整路径
ReadBuffer 命中
// 不论如何,先让我们看看 `ReadBuffer` 的源代码:
auto BufferManager::ReadBuffer(FileId file_id, BlockId block_id) -> Result<BufferHandle> {
// ReadBuffer 命中情况
if (!init_status_.ok()) return init_status_;
const BufferTag tag{file_id, block_id};
auto resident_hit = TryReadResidentHit(tag);
if (resident_hit.has_value()) return std::move(resident_hit.value());
// 下面是 miss 情况,下一段再看
auto registration = miss_coordinator_->RegisterOrJoin(tag);
if (!registration.is_owner) return AwaitJoinedMiss(tag, registration.state);
auto handle = TryReadResidentHit(tag);
if (!handle.has_value()) return LoadMissOwnerBuffer(tag, registration.state);
miss_coordinator_->Complete(tag, registration.state, Status::Ok(), handle->frame_id());
return std::move(handle.value());
}
其实看代码已经和看自然语言一样轻松,我目前的习惯是很喜欢这种“卫函数下降式”的风格的代码。一行一行看就好了。不过这样看代码,意思很直接:
- 检查
BufferManager初始化是否成功。 - 用
(file_id, block_id)组装一个BufferTag。 - 先尝试走 resident hit。
- 如果命中,直接返回 BufferHandle,不会进入 miss 路径。
- 如果没命中,我们后面再说。
真正的命中逻辑先到 TryReadResidentHit 中:
auto BufferManager::TryReadResidentHit(const BufferTag &tag) -> std::optional<BufferHandle> {
auto frame_id = page_table_->LookupFrameId(tag);
if (!frame_id.has_value()) return std::nullopt;
auto handle = TryPinResidentFrame(frame_id.value(), tag);
if (!handle.has_value()) return std::nullopt;
observer_->RecordResidentHit(tag);
return std::move(handle.value());
}
这里做两件事:
- 先查 page table,看这个
BufferTag有没有对应的FrameId。 - 如果页表里根本没有,就不是 hit。
- 如果页表里有,也还不能立刻返回,还要继续验证这个 frame 当前状态是否真的可读。
- 成功查到这个页是 resident,打一次
telemetry的 resident hit 埋点。
所以到这里已经可以先看到一个非常重要的事实:
BufferTag->FrameId是由 page table 维护的。- 但 page table 命中,不等于这个页一定已经 ready。
真正决定能不能返回 handle 的,是 TryPinResidentFrame。
auto BufferManager::TryPinResidentFrame(FrameId frame_id, const BufferTag &tag) -> std::optional<BufferHandle> {
BufferDescriptor &descriptor = descriptors_[frame_id];
{
std::lock_guard<std::mutex> descriptor_guard(descriptor.latch);
if (!buffer_descriptor_state::IsResidentFrameMatch(descriptor, tag)) return std::nullopt;
++descriptor.pin_count;
}
replacer_->RecordAccess(frame_id);
replacer_->SetEvictable(frame_id, false);
return BufferHandle(this, frame_id, tag, GetFrameData(frame_id), page_size_);
}
这里是命中路径最关键的一步。它做了三件事:
- 锁住对应
BufferDescriptor。 - 检查这个 frame 是否真的满足是 resident 且可读的条件。
- 如果满足,
pin_count++,然后返回一个 pinned handle。
这个检查逻辑属于 buffer_descriptor_state 中:
bool IsResidentFrameMatch(const BufferDescriptor &descriptor, const BufferTag &tag) {
if (descriptor.state != BufferFrameState::kResident) return false;
if (!descriptor.is_valid) return false;
if (descriptor.io_in_flight) return false;
if (descriptor.tag != tag) return false;
return true;
}
也就是说,命中必须同时满足:
state == kResidentis_valid == trueio_in_flight == falsedescriptor.tag == tag
这说明 page table 只是“索引”,BufferDescriptor 才是最终状态真相。一旦满足条件然后,告诉 replacer 这个 frame 被访问过,并且它现在被 pin 住了,不可驱逐。
最后一步是构造 handle,返回的 BufferHandle 里放的一些基础语义以及这一帧对应的数据指针,此时 handle 还没有拿内容锁。真正访问内容时才会延迟加锁。data() 拿 shared lock,mutable_data() 拿 unique lock。
所以总结命中路径:
ReadBuffer先把(file_id, block_id)组装成BufferTag- 再查 page table 找 FrameId
- 然后锁住对应
BufferDescriptor验证该 frame 是否真的是可用的 resident frame - 如果是,就增加
pin_count,通知replacer这个 frame 当前不可驱逐,记录一次 hit 埋点,并返回一个指向该 frame 的BufferHandle。
即:
ReadBuffer
- ➜
TryReadResidentHit:查看命中逻辑 - ➜ 开始拿
BufferTag找 Frame 验证是否可读 - ➜
LookupFrameId:查 page table,看有没有对应的FrameId - ➜
TryPinResidentFrame:处理和 handle 相关的事务 - ➜ 处理 replacer 策略
- ➜ 制作 handle 返回
ReadBuffer 未命中
miss 路径比 hit 路径更加复杂,miss 路径才真正把这个系统的协调逻辑暴露出来,ReadBuffer 未命中的情况比命中多了三层复杂性:
- 同页并发
miss不能重复读盘 - 需要找一个可用
frame,必要时驱逐旧页 - 异步读完成前,页表和
descriptor会进入一个“已预留但未就绪”的中间状态
// 就是这几块, miss 路径比 hit 路径更加复杂,miss 路径才真正把这个系统的协调逻辑暴露出来
auto registration = miss_coordinator_->RegisterOrJoin(tag);
if (!registration.is_owner) return AwaitJoinedMiss(tag, registration.state);
// 下面是 owner 的逻辑
auto handle = TryReadResidentHit(tag);
if (!handle.has_value()) return LoadMissOwnerBuffer(tag, registration.state);
miss_coordinator_->Complete(tag, registration.state, Status::Ok(), handle->frame_id());
return std::move(handle.value());
这几行其实已经把 miss 路径的骨架全写出来了。
第一层:先分 owner 和 joiner
当 resident hit 失败后,不会立刻去读盘,而是先经过 miss_coordinator_。这里的目的只有一个:同一个 BufferTag 的并发 miss,只允许一个线程真的去做装载其他线程不要重复读同一页,只等结果就行。所以这里会出现两种角色:
- owner:第一个来的人,负责真正装页
- joiner:后来的线程,只等待 owner 的结果
如果当前线程不是 owner,就直接走:AwaitJoinedMiss(tag, registration.state);如果当前线程是 owner,先做类似之前的:TryReadResidentHit 逻辑,这和 hit 路径的函数是一样的。这很关键,因为在第一次 hit 检查失败到成功注册成 miss state 并成为 owner 之间,仍然存在一个竞争窗口。此时更早的一次 miss 可能已经完成,并把这个页装进内存了。所以 owner 也要再查一次 resident hit,避免重复工作。
第二层:joiner 在等什么?
auto BufferManager::AwaitJoinedMiss(const BufferTag &tag, const std::shared_ptr<BufferManagerMissState> &state) -> Result<BufferHandle> {
Result<FrameId> wait_result = miss_coordinator_->Wait(state);
if (!wait_result.ok()) return wait_result.status();
FrameId frame_id = wait_result.value();
Status wait_status = WaitForFrameReady(frame_id);
if (!wait_status.ok()) return wait_status;
auto handle = TryPinResidentFrame(frame_id, tag);
if (!handle.has_value()) return Status::NotFound("buffer not resident after load completion");
observer_->RecordJoinedMissHit(tag);
return std::move(handle.value());
}
joiner 实际上做了三件事:
- 先等待 owner 告诉它,这次 miss 的最终结果是什么
- 如果成功,再等待对应 frame 真正进入 ready 状态;失败则将错误继续向上传播。
- 最后自己重新 pin 这个 resident frame,并拿到属于自己的 BufferHandle
这说明 joiner 并不是直接复用 owner 的 handle,而是在 owner 完成装载后,再以正常 resident page 的方式重新进入访问路径。
第三层:owner 才真正负责装载
如果 owner 的二次 hit 检查依然失败,就会进入真正的装载路径:
auto BufferManager::LoadMissOwnerBuffer(const BufferTag &tag, const std::shared_ptr<BufferManagerMissState> &state) -> Result<BufferHandle> {
observer_->RecordReadMiss(tag);
Result<FrameReservation> reserve_result = ReserveFrameForTag(tag);
if (!reserve_result.ok()) {
miss_coordinator_->Complete(tag, state, reserve_result.status(), kInvalidFrameId);
return reserve_result.status();
}
Result<FrameId> frame_result = CompleteReservation(tag, reserve_result.value());
if (!frame_result.ok()) {
miss_coordinator_->Complete(tag, state, frame_result.status(), kInvalidFrameId);
return frame_result.status();
}
const FrameId frame_id = frame_result.value();
miss_coordinator_->Complete(tag, state, Status::Ok(), frame_id);
return BufferHandle(this, frame_id, tag, GetFrameData(frame_id), page_size_);
}
这里的逻辑可以概括为:
- 记录一次真正的 read miss
- 为这个 tag 预留一个可用 frame
- 完成预留,包括必要的驱逐、刷盘和异步读
- 装载成功后,通过
miss_coordinator_唤醒所有 joiner - owner 自己返回一个新的
BufferHandle
具体我们将在后续章节展开,这说明 owner 的职责不只是简单“去读盘”,而是完整负责找 frame、处理 victim、推进 descriptor 状态机、等待异步 I/O 完成、通知 joiner。
miss 路径的总结构
所以,从顶层视角来看,ReadBuffer 未命中的完整控制流可以概括为:
- 先通过
miss_coordinator_协调并发 miss - owner / joiner 分流
- joiner 负责等待并重新 pin resident frame
- owner 负责预留 frame、处理驱逐、完成异步读
- 最后所有线程都以
BufferHandle的形式回到统一的访问语义中
因此,miss 路径本质是一个同时涉及并发协调、frame 生命周期管理、异步 I/O 和状态机推进的完整流程。
同页并发未命中的本质
恭喜你,其实,我们刚刚走过 miss 的路径,解决了一个非常经典的并发问题——同页并发缺页问题,其会直接导致重复缺页和无谓的并发放大,严重时会表现出惊群效应:
如果多个线程同时请求同一个还不在内存中的页面,而系统没有做缺页协调,那么每个线程都可能自己发起一次磁盘读取。这样首先会造成重复 I/O,浪费带宽和增加延迟;其次会带来页面安装阶段的竞争,比如多个线程都试图把同一个逻辑页映射到缓冲池,容易导致状态不一致,或者让后续的 pin count、页表映射、错误恢复逻辑变得很难处理。
具体的所有权登记问题我们可以后面再说,至少我们在 BufferManager 层面已经掌握了怎么解决它的一个方法:
- 同一个
BufferTag只允许一个 owner 真正装页 - 其他线程作为 joiner 等待结果
- joiner 不复用 owner 的 handle,而是在页 ready 后重新 pin
预留与驱逐
当 owner 确认这次 ReadBuffer 确实无法通过 resident hit 解决后,就会进入真正的装载路径。其中第一步不是立刻读盘,而是先为这个 BufferTag 找到一个可用的 frame。如果 free list 中还有空闲 frame,就直接使用;如果没有,就必须从 replacer 中选一个 victim,并在必要时先处理旧页的刷盘与状态恢复。对应的入口在 LoadMissOwnerBuffer 中:
Result<FrameReservation> reserve_result = ReserveFrameForTag(tag);
if (!reserve_result.ok()) ...
Result<FrameId> frame_result = CompleteReservation(tag, reserve_result.value());
if (!frame_result.ok()) ...
可以看到,这里的流程被明确拆成两段:
ReserveFrameForTag:先预留一个 frameCompleteReservation:再完成这次预留,包括必要的驱逐、刷盘和读入,我们后面再说。
先找一个候选 frame
ReserveFrameForTag 的逻辑并不复杂,它会不断尝试拿到一个 candidate frame,直到成功预留为止。
auto BufferManager::ReserveFrameForTag(const BufferTag &tag) -> Result<FrameReservation> {
while (true) {
Result<FrameId> frame_result = AcquireReservationFrame();
if (!frame_result.ok()) return frame_result.status();
auto reservation = TryReserveFrameForTag(frame_result.value(), tag);
if (reservation.has_value()) return std::move(reservation.value());
}
}
这里的关键点是拿到 candidate frame,不等于已经成功预留。因为一个 frame 即使来自 free list 或 replacer,也仍然可能正处于不适合被接管的状态,比如还有 flush 在飞、I/O 尚未完成等,所以还必须进一步检查。
candidate frame 从哪里来?
这一部分的逻辑在 AcquireReservationFrame 中,candidate frame 的来源只有两个:
free_list_replacer_->Victim(...)
也就是说,系统会优先使用真正空闲的 frame;只有 free list 用完时,才会进入驱逐路径。这说明“驱逐”不是 miss 的默认行为,而是缓冲池没有空位时才发生的退路。
什么叫成功预留?
真正的预留动作发生在 TryReserveFrameForTag 中。这里会锁住目标 frame 对应的 BufferDescriptor,检查它当前是否满足接管条件。如果满足,就构造一个 FrameReservation,记录这次预留之前的旧页上下文,并把新页安装到页表中,然后把 descriptor 推进到 kLoading 状态。这意味着:
- 页表里已经出现了新的 BufferTag -> FrameId
- 但这个 frame 还没有真正变成 resident page
- descriptor 此时只是进入了“已经预留、正在装载”的中间状态
这也就是前面提到的页表和 descriptor 进入已预留但未就绪状态的来源。
为什么还需要返回 FrameReservation?
因为 FrameReservation 不是 frame 本身,而是这次 frame 预留操作附带保存下来的旧状态。如果被接管的 frame 之前已经装有旧页,那么这里会记录:
- 旧页的
BufferTag - 旧页是否
dirty - 旧页的
dirty_generation
这样做的目的,是让后续驱逐失败时仍然有机会恢复旧页映射和 descriptor 状态,而不是把原来的页上下文直接丢掉。
什么时候真的进入驱逐?
只有当 candidate frame 不是 free frame,而是一个已经承载旧页的 resident frame 时,才算真正进入驱逐路径。此时如果旧页是脏页,就不能直接覆盖其内容,而必须先刷盘;只有刷盘成功后,新的逻辑页才能安全装入这个 frame。因此,从本质上说,驱逐需要:
- 先保存旧页上下文
- 必要时先刷回旧页
- 刷回成功后再发起新页读取
- 失败时还能根据
reservation做恢复
小结
所以,miss 路径中的 frame 预留与驱逐,本质上是在解决一个问题:
当一个逻辑页必须进入内存,而缓冲池未必还有空位时,系统如何安全地为它腾出一个可用 frame,并保证旧页状态、新页安装、并发访问和失败恢复都保持一致。
从控制流上看,这一阶段可以先压缩理解为:
- 先找 candidate frame
- 尝试预留
- 如有旧页则记录
reservation - 如有必要则触发驱逐与刷盘
- 最终把
descriptor推进到kLoading,为后续异步读做好准备
异步 I/O 完成后
后端完成 I/O 了还要干啥,BufferManager 能不能直接歇了。
后端完成了,只说明一句话:那 4096 字节已经读进某块内存了。但对 BufferManager 来说,这还远远不够。因为它还要负责这些事:
- 这个 frame 现在能不能从
kLoading变成kResident descriptor.io_in_flight要不要清掉is_valid要不要设成 true- 失败时要不要回滚页表和 frame 状态
- 等这个页的 joiner 要不要被唤醒
- owner 最终能不能安全返回
BufferHandle
所以异步 I/O 完成后还得干一堆收尾。
owner 线程先把页读请求异步提交给 DiskBackend,再通过 completion_dispatcher_ 按 request_id 等待完成;等完成后,再把对应 frame 从 kLoading 推进到 kResident。
哪里标志着是异步 I/O 完成后
从 CompleteReservation 开始,也就是我们刚刚提到的 LoadMissOwnerBuffer 的后半部分。
auto BufferManager::CompleteReservation(const BufferTag &tag, const FrameReservation &reservation) -> Result<FrameId>{
const FrameId frame_id = reservation.frame_id;
Status flush_status = FlushReservedVictim(reservation);
if (!flush_status.ok()) return RestoreEvictionFailure(reservation, flush_status);
Status read_status = ReadReservedPage(frame_id, tag);
if (!read_status.ok()) return AbortLoadReservation(frame_id, tag, read_status);
CompleteLoadedFrame(frame_id);
replacer_->RecordAccess(frame_id);
replacer_->SetEvictable(frame_id, false);
if (!reservation.had_evicted_page) {
observer_->RecordLoadCompletion(tag);
return frame_id;
}
observer_->RecordLoadCompletion(tag, reservation.evicted_tag);
return frame_id;
}
这里顺序很重要:
- 如果旧 victim 是脏页,先 flush
- 然后才读新页:ReadReservedPage(frame_id, tag)
- 如果读失败,就 AbortLoadReservation
- 如果读成功,才继续把 frame “转正”
所以异步读不是独立章节,它是 CompleteReservation 的一部分。
ReadReservedPage 干了什么?
ReadReservedPage 是异步读请求的提交与等待的骨架:
- 先把 descriptor 标成
io_in_flight = true - 再把读请求提交给 disk_backend_,拿到 request_id
Register(request_id)告诉 completion dispatcher:我之后要等这个 requestWait(request_id)当前 owner 线程在这里阻塞,直到这个 request 的 completion 到来
这说明在 backend 真正完成之前,这个 frame 已经明确处在:
state = kLoadingio_in_flight = true
所以别的线程即使从 page table 查到了它,也不能把它当作 resident page 直接用。
所以要注意一个容易误解的点:这里虽然叫异步 I/O,但对 owner 线程来说,它仍然会同步等待结果。异步的是 backend 和 completion 路由机制,不是说 owner 发完就完全不管了。
disk_backend_->SubmitRead(…) 是怎么回事?
接口定义在 DiskBackend 类中:
virtual auto SubmitRead(
const BufferTag &tag,
std::byte *out,
std::size_t size
) -> Result<uint64_t> = 0;
这说明 backend 接收的是:
- 读哪个逻辑页:
tag - 把数据读到哪块内存:
out - 读多大:
size - 返回一个
request_id
也就是说,页内容是直接读进目标 frame 对应的内存里的。不是先读到临时 buffer,再拷贝进去。
如果看 PosixDiskBackend,SubmitRead 最终会把请求塞进队列,后台 worker 线程执行 pread。所以哪怕当前是 POSIX fallback,这套接口语义仍然是“异步请求 + completion”。
completion dispatcher 到底在做什么?
这是这一段最关键最抽象的部分。为什么要 completion 分发我们具体后面展开,但现在先理解,所有 backend completion 都统一由 dispatcher 线程消费,业务线程不要自己直接去抢 completion。
核心路径在 Run() 中
void BufferManagerCompletionDispatcher::Run() {
while (true) {
...
Result<DiskCompletion> completion_result = disk_backend_->PollCompletion();
...
DiskCompletion completion = completion_result.value();
auto &state = request_states_[completion.request_id];
state.completed = true;
state.status = completion.status;
...
cv_.notify_all();
}
}
也就是说 dispatcher 线程会:
- 调
disk_backend_->PollCompletion() - 拿到某个
DiskCompletion - 根据
completion.request_id找到等待这个请求的状态槽 - 标记它已经完成
- 唤醒对应等待者
所以 owner 线程在 completion_dispatcher_->Wait(request_id) 里等的,不是 backend 本身,而是 dispatcher 帮它路由过来的完成结果。
异步 I/O 完成后真正发生了什么?
当 completion_dispatcher_->Wait(request_id) 返回成功后,说明:
- 这个读请求已经真正完成
- 数据已经被 backend 写进
frame_pool_->GetFrameData(frame_id)指向的那块 frame 内存 - 但此时 frame 还没有自动变成 resident
也就是说,I/O 完成 ≠ frame 已经可用,真正把它变成可用页的,是后面的状态推进。这个时候回到 CompleteReservation 后半段里看看它怎么转正这个 frame。在 ReadReservedPage 成功返回后,紧接着会有:
CompleteLoadedFrame(frame_id)replacer_->RecordAccess(frame_id)replacer_->SetEvictable(frame_id, false)
所以异步 I/O 完成后,最核心的行为是:
- 异步读请求先被提交到 backend,返回
request_id - completion dispatcher 统一消费 backend completion,并按
request_id唤醒等待者 - I/O 成功后,owner 线程再把对应 frame 从
kLoading推进到kResident
BufferHandle 的使用与释放
BufferHandle 的使用与释放比刚刚这几节简单不少。因为它的主线很短,核心就 4 件事:
BufferHandle是怎么构造出来的data()/mutable_data()怎么拿锁Reset()/ 析构时怎么 unpin- 为什么它是 RAII + move-only
回顾一下,BufferHandle 是怎么来的?ReadBuffer 命中或 miss 成功后返回 BufferHandle,它保存 manager / frame_id / tag / data / size。
为什么它是 RAII?因为其使得访问结束时不需要调用者手动记住一堆收尾逻辑,作用域结束自动释放锁并 unpin。
为什么它是 move-only?不能拷贝,是为了避免一个访问句柄被无意复制,从而破坏 pin/unpin 与锁生命周期的一一对应关系。因此这是使得生命周期和 pin/unpin 强绑定。
data() 和 mutable_data()
auto BufferHandle::data() const -> const std::byte * {
if (manager_ == nullptr) return nullptr;
return manager_->AcquireReadPointer(const_cast<BufferHandle *>(this));
}
auto BufferHandle::mutable_data() -> std::byte * {
if (manager_ == nullptr) return nullptr;
return manager_->AcquireWritePointer(this);
}
从代码上看非常明显,data() 懒获取 shared lock,mutable_data() 升级为 unique lock(准确来说是先放掉读锁,再拿写锁),可见,handle 本身不在构造时自动拿内容锁,而是通过这两个函数拿锁。
Reset() 和析构
BufferHandle::~BufferHandle() { Reset(); }
void BufferHandle::Reset() {
if (manager_ == nullptr) return;
if (read_lock_.owns_lock()) read_lock_.unlock();
if (write_lock_.owns_lock()) write_lock_.unlock();
BufferManager *manager = manager_;
manager_ = nullptr;
std::ignore = manager->ReleaseFrame(frame_id_);
frame_id_ = kInvalidFrameId;
data_ = nullptr;
size_ = 0;
}
也很直接,先释放 read_lock_ / write_lock_,再调用 BufferManager::ReleaseFrame(frame_id_),这将最终导致 pin_count--,并把上下文清空,使 handle 失效。
这一节最关键的一句
BufferHandle不是 page 本身,而是某个 resident frame 的一次受控访问句柄。
遥测埋点触发
这里面也是我们可观测性的一部分了,先看总结构:
class TelemetrySink;
class BufferManagerObserver {
public:
explicit BufferManagerObserver(std::shared_ptr<TelemetrySink> telemetry_sink);
void RecordResidentHit(const BufferTag &tag) const;
void RecordJoinedMissHit(const BufferTag &tag) const;
void RecordReadMiss(const BufferTag &tag) const;
void RecordReservedVictimFlush(const BufferTag &tag) const;
void RecordLoadCompletion(const BufferTag &tag) const;
void RecordLoadCompletion(
const BufferTag &tag,
const BufferTag &evicted_tag
) const;
void RecordSuccessfulFlush(const BufferTag &tag) const;
private:
void RecordHit(const BufferTag &tag) const;
void RecordMiss(const BufferTag &tag) const;
void RecordDiskRead(const BufferTag &tag) const;
void RecordDiskWrite(const BufferTag &tag) const;
void RecordEviction(const BufferTag &tag) const;
void RecordDirtyFlush(const BufferTag &tag) const;
std::shared_ptr<TelemetrySink> telemetry_sink_;
};
可见,BufferManager 不直接操作 TelemetrySink,而是通过 BufferManagerObserver 组件发语义化事件,BufferManagerObserver 再把这些事件翻译成更底层的 RecordHit / RecordMiss / RecordDiskRead,最后 TelemetrySink 决定这些事件怎么落地。
BufferManagerObserver 可以理解成是数据面里的埋点适配层。它对外暴露的是这种更贴近 buffer pool 语义的接口,使得 BufferManager 里不会直接写:telemetry_sink_->RecordHit(...) 而是写 observer_->RecordResidentHit(tag),这层的价值就在于让 BufferManager 说业务语义,让 observer 负责翻译。
怎么翻译事件的,其实看代码非常简单:
void BufferManagerObserver::RecordResidentHit(const BufferTag &tag) const {
RecordHit(tag);
}
void BufferManagerObserver::RecordJoinedMissHit(const BufferTag &tag) const {
RecordHit(tag);
}
void BufferManagerObserver::RecordReadMiss(const BufferTag &tag) const {
RecordMiss(tag);
}
其实就是将 ResidentHit,JoinedMissHit 最终记成 hit,ReadMiss 最终记成 miss,这里已经能看出一个设计倾向,当前 telemetry 更关注计数语义,不是把每类高层事件都单独保留下来。例如 joined miss hit 在 sink 层并没有单独计数器,它最终仍算作一次 buffer_hit。
复杂一点的事件是组合出来的
看几个复杂一点的事件:
void BufferManagerObserver::RecordReservedVictimFlush(const BufferTag &tag) const {
RecordDiskWrite(tag);
RecordDirtyFlush(tag);
}
void BufferManagerObserver::RecordLoadCompletion(const BufferTag &tag) const {
RecordDiskRead(tag);
}
void BufferManagerObserver::RecordLoadCompletion(const BufferTag &tag, const BufferTag &evicted_tag) const {
RecordDiskRead(tag);
RecordEviction(evicted_tag);
}
void BufferManagerObserver::RecordSuccessfulFlush(const BufferTag &tag) const {
RecordDiskWrite(tag);
RecordDirtyFlush(tag);
}
这说明旧 victim 被刷回成功在 telemetry 看来,这是一次 disk_write + dirty_flush。
RecordLoadCompletion 的意思则是一次装页成功完成,telemetry 里记作一次 disk_read,或第二种情况,装页成功并且这是通过驱逐旧页腾出来的,telemetry 在这里会同时记一次 disk_read 和一次 eviction。
RecordSuccessfulFlush 则是正常 flush 成功 telemetry 里也是一次 disk_write + dirty_flush。
所以现在可见:BufferManagerObserver 并不是一对一转发事件,而是在高层语义和底层计数之间做了一层映射,有些业务事件会被翻译成多个底层遥测计数。
TelemetrySink
class TelemetrySink {
public:
virtual ~TelemetrySink() = default;
// Records a cache hit for the given page access.
void RecordHit(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::buffer_hits)) return;
DoRecordHit(tag);
}
// Records a cache miss for the given page access.
void RecordMiss(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::buffer_misses)) return;
DoRecordMiss(tag);
}
// Records a completed disk read.
void RecordDiskRead(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::disk_reads)) return;
DoRecordDiskRead(tag);
}
// Records a completed disk write.
void RecordDiskWrite(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::disk_writes)) return;
DoRecordDiskWrite(tag);
}
// Records an eviction of a resident page.
void RecordEviction(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::evictions)) return;
DoRecordEviction(tag);
}
// Records a dirty-page flush event.
void RecordDirtyFlush(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::dirty_flushes)) return;
DoRecordDirtyFlush(tag);
}
// Returns a point-in-time snapshot of all exported counters.
TelemetrySnapshot Snapshot() const {
if (fast_path_counters_ != nullptr) return ReadCountersSnapshot(*fast_path_counters_);
return DoSnapshot();
}
protected:
explicit TelemetrySink(TelemetryCounters *fast_path_counters = nullptr)
: fast_path_counters_(fast_path_counters) {}
static auto ReadCountersSnapshot(const TelemetryCounters &counters)
-> TelemetrySnapshot {
return TelemetrySnapshot{
counters.buffer_hits.load(std::memory_order_relaxed),
counters.buffer_misses.load(std::memory_order_relaxed),
counters.disk_reads.load(std::memory_order_relaxed),
counters.disk_writes.load(std::memory_order_relaxed),
counters.evictions.load(std::memory_order_relaxed),
counters.dirty_flushes.load(std::memory_order_relaxed),
};
}
virtual void DoRecordHit(const BufferTag &tag) = 0;
virtual void DoRecordMiss(const BufferTag &tag) = 0;
virtual void DoRecordDiskRead(const BufferTag &tag) = 0;
virtual void DoRecordDiskWrite(const BufferTag &tag) = 0;
virtual void DoRecordEviction(const BufferTag &tag) = 0;
virtual void DoRecordDirtyFlush(const BufferTag &tag) = 0;
virtual TelemetrySnapshot DoSnapshot() const = 0;
private:
bool RecordFastPath(std::atomic<uint64_t> TelemetryCounters::*counter) {
if (fast_path_counters_ == nullptr) return false;
(fast_path_counters_->*counter).fetch_add(1, std::memory_order_relaxed);
return true;
}
TelemetryCounters *fast_path_counters_{nullptr};
};
直接看代码,它暴露的底层事件类型以及最后的 Snapshot(),以及当前导出的快照结构:
struct TelemetrySnapshot {
uint64_t buffer_hits{0};
uint64_t buffer_misses{0};
uint64_t disk_reads{0};
uint64_t disk_writes{0};
uint64_t evictions{0};
uint64_t dirty_flushes{0};
};
所以 telemetry 目前的本质是轻量级进程内计数器,而不是事件流系统。但 TelePath 的大方向是“可观测性”,当前代码里的这一层其实还比较朴素,是后续将重点筑牢的部分。
fast path counter
这段非常关键:
void RecordHit(const BufferTag &tag) {
if (RecordFastPath(&TelemetryCounters::buffer_hits)) return;
DoRecordHit(tag);
}
意思是如果 sink 提供了 fast_path_counters_,那就直接对原子计数器 fetch_add(1, relaxed),根本不走虚函数细节逻辑,也就是说,当前 telemetry 设计非常明确地在做一件事:缓存热路径上优先走最快的原子计数,尽量减少额外开销。
两个 sink
class CounterTelemetrySink final : public TelemetrySink {
public:
CounterTelemetrySink() : TelemetrySink(&counters_) {}
protected:
void DoRecordHit(const BufferTag &) override {}
void DoRecordMiss(const BufferTag &) override {}
void DoRecordDiskRead(const BufferTag &) override {}
void DoRecordDiskWrite(const BufferTag &) override {}
void DoRecordEviction(const BufferTag &) override {}
void DoRecordDirtyFlush(const BufferTag &) override {}
auto DoSnapshot() const -> TelemetrySnapshot override {
return ReadCountersSnapshot(counters_);
}
private:
TelemetryCounters counters_{};
};
CounterTelemetrySink 的特点是,构造时把自己的 TelemetryCounters 传给基类,所以 RecordFastPath(...) 会成功,DoRecordXxx(...) 全是空实现。这说明当前默认的计数型 sink,本质上完全靠 fast-path atomic counters 工作。不保存按页明细,不做复杂处理,只累计总数。
class NoOpTelemetrySink final : public TelemetrySink {
public:
NoOpTelemetrySink() = default;
protected:
void DoRecordHit(const BufferTag &) override {}
void DoRecordMiss(const BufferTag &) override {}
void DoRecordDiskRead(const BufferTag &) override {}
void DoRecordDiskWrite(const BufferTag &) override {}
void DoRecordEviction(const BufferTag &) override {}
void DoRecordDirtyFlush(const BufferTag &) override {}
auto DoSnapshot() const -> TelemetrySnapshot override {
return TelemetrySnapshot{};
}
};
NoOpTelemetrySink 就是故意丢掉所有事件。而且 BufferManagerObserver 构造时如果拿到空指针,会自动 fallback 到 NoOpTelemetrySink,这意味着 telemetry 在架构上是可选能力,不会阻止数据面运行。
总结
BufferManager不直接依赖具体 telemetry 实现,而是通过BufferManagerObserver发出高层语义事件。BufferManagerObserver会把这些高层事件翻译成较少的一组底层计数语义,例如hit/miss/disk_read/disk_write/eviction/dirty_flush。- 当前
TelemetrySink的主实现是CounterTelemetrySink,它通过原子计数器走 fast path,只维护总量,不保留逐页事件明细。 - 因此,当前这套
telemetry更像是一个低开销的 in-process counter layer,而不是完整的事件流观测系统。
当前 TelePath 的遥测层已经实现了数据面与观测面解耦的基本结构,但观测结果目前仍以低开销聚合计数为主,距离完整的共享内存事件流还有明显演进空间。未来将对 SDK / monitor plane 展开。
写回与刷盘完整路径
脏页
在 buffer pool 语义里,脏页就是这个页在内存里被改过,但这些改动还没同步回磁盘。
所以 dirty 的本质是内存中的内容已经和磁盘上的版本不一致了。在 TelePath 里,这个状态记录在 BufferDescriptor 里:
is_dirty、dirty_generation,我们之前已经见过它们了。
回顾 BufferHandle::mutable_data(),它只是转给 BufferManager::AcquireWritePointer(this)。而它做的事情本质上只是:
- 校验
handle - 获取
content_latch的 unique lock - 返回可写指针
它没有改 is_dirty,也没有动 dirty_generation。现在这版实现里,拿到写权限和正式声明这个页已脏是两步分开的。这样设计的含义是:你可以拿写锁准备改,但只有当你确认这次写真的改变了页内容时,才调用 MarkBufferDirty(handle),这是个显式协议,不是自动检测。
真正让页变脏的是 BufferManager::MarkBufferDirty(const BufferHandle &handle)。
auto BufferManager::MarkBufferDirty(const BufferHandle &handle) -> Status {
Status validate_status = ValidateOwnedHandle(handle);
if (!validate_status.ok()) return validate_status;
Result<bool> dirty_result = MarkFrameDirty(handle.frame_id(), handle.tag());
if (!dirty_result.ok()) return dirty_result.status();
if (dirty_result.value()) {
dirty_page_count_.fetch_add(1, std::memory_order_acq_rel);
NotifyCleaner();
}
return Status::Ok();
}
这说明它做了三件事:
- 先检查这个 handle 合不合法
- 真正去改对应 frame 的 dirty 状态
- 如果这个页是第一次从 clean 变 dirty,就增加全局
dirty_page_count_,并通知 cleaner
可见 dirty 标记会影响整个系统的后台刷盘行为。
auto BufferManager::MarkFrameDirty(FrameId frame_id, const BufferTag &tag) -> Result<bool> {
BufferDescriptor &descriptor = descriptors_[frame_id];
std::lock_guard<std::mutex> guard(descriptor.latch);
if (!descriptor.is_valid || descriptor.state != BufferFrameState::kResident || descriptor.tag != tag) return Status::InvalidArgument("buffer handle refers to an invalid frame");
const bool became_dirty = !descriptor.is_dirty;
++descriptor.dirty_generation;
descriptor.is_dirty = true;
return became_dirty;
}
这段特别值得理解。它做了两件核心事:
descriptor.is_dirty = true:这个很好理解,表示这个 resident page 现在是脏页。++descriptor.dirty_generation:这个更有意思。它表示每次显式标脏,都会推进一个版本号。这个版本号后面在 flush 路径里非常重要,因为它用来判断某次 flush 针对的是不是当前这版脏数据;如果 flush 过程中页又被改了,那旧 flush 完成后能不能清 dirty。即是为了防止旧的刷盘结果错误地把新的修改覆盖掉。
接下来看这句:const bool became_dirty = !descriptor.is_dirty;
然后只有 became_dirty == true 时,外层才:dirty_page_count_.fetch_add(1, ...)、NotifyCleaner();。这说明:
- 一个页从 clean -> dirty,只算新增 1 个脏页
- 之后它再被多次修改,不会反复增加 dirty page count
因为 dirty_page_count_ 统计的是当前有多少个 resident dirty pages,不是发生了多少次写。这个区别很重要。
所以最后,脏页怎么来的?现在可以直接用一句话回答:
页之所以变脏,是因为调用者先通过 mutable_data() 获取可写访问,再在确认修改发生后显式调用 MarkBufferDirty(handle),由 BufferManager 将对应 frame 的 is_dirty 设为 true,并推进 dirty_generation。
mutable_data()只是给你写权限MarkBufferDirty()才是真正宣布“这个页脏了”
总结:
在 TelePath 中,页不会因为拿到了可写指针就自动变脏。BufferHandle::mutable_data() 的作用只是获取页面内容的独占访问权,并返回可写指针;它本身不会修改 BufferDescriptor 中的 dirty 状态。真正让页变脏的是调用者随后显式调用 BufferManager::MarkBufferDirty(handle)。
MarkBufferDirty 会先校验 handle 的合法性,然后进入 MarkFrameDirty(frame_id, tag)。在这一层里,系统会锁住对应 frame 的 BufferDescriptor,确认该页当前仍是有效的 resident frame,然后把 is_dirty 设为 true,并将 dirty_generation 加一。这里的 dirty_generation 可以理解为这页脏状态的版本号,它的作用不是计数“写了多少字节”,而是帮助后续 flush 路径判断:某次刷盘针对的是否还是当前这版脏数据。
如果一个页是第一次从 clean 变成 dirty,BufferManager 还会增加全局的 dirty_page_count_,并通知后台 cleaner。也就是说,dirty 标记不仅是一个局部 frame 状态变化,它还会影响整个写回系统何时开始介入。
单页写回与刷盘
脏页产生后,真正负责把它写回磁盘的入口是 FlushBuffer(handle)。从源码看,这条路径会先校验 handle,再决定是否能使用一个稳定的数据源直接做 snapshot,之后构造 flush task,交给 flush scheduler 提交写请求,最后在 flush 完成时收尾并更新 dirty 状态。
FlushBuffer
FlushBuffer 的逻辑很短,但它决定了后面整条刷盘路径怎么走:
auto BufferManager::FlushBuffer(const BufferHandle &handle) -> Status {
Status validate_status = ValidateOwnedHandle(handle);
if (!validate_status.ok()) return validate_status;
if (handle.write_lock_.owns_lock() || handle.read_lock_.owns_lock()) return FlushFrameWithStableSource(handle.frame_id(), handle.data_);
return FlushFrame(handle.frame_id());
}
- 先确认这个 handle 仍然合法,并且确实属于当前
BufferManager - 如果 handle 当前已经持有内容锁,就把这块 frame 内存视作一个稳定的数据源
- 如果没有稳定源,就走普通的
FlushFrame路径
这里所谓的 stable source,本质上是:当前调用者已经持有这页的内容锁,因此这次 snapshot 可以直接基于当前可见的内存内容构造,而不用担心拷贝期间被并发修改。
FlushFrameWithStableSource 最终进入前台 flush 循环
无论有没有 stable source,最后都会进入 RunForegroundFlush:
auto BufferManager::FlushFrameWithStableSource(FrameId frame_id, const std::byte *stable_data) -> Status {
if (frame_id >= pool_size_) return Status::InvalidArgument("invalid frame id");
return RunForegroundFlush(frame_id, stable_data);
}
auto BufferManager::RunForegroundFlush(FrameId frame_id, const std::byte *stable_data) -> Status {
while (true) {
Result<std::shared_ptr<BufferManagerFlushTask>> schedule_result = TryScheduleFlushTask(frame_id, stable_data, nullptr, false);
if (!schedule_result.ok()) return schedule_result.status();
if (schedule_result.value() == nullptr) return Status::Ok();
Status wait_status = flush_scheduler_->Wait(schedule_result.value());
if (!wait_status.ok()) return wait_status;
}
}
这里可以看到:
- foreground flush 会不断尝试调度 flush task
- 如果当前 frame 已经不需要 flush,就直接返回 Ok
- 如果成功构造了 task,就同步等待这次 flush 完成
所以这里虽然底层是异步写请求,但对调用 FlushBuffer 的线程来说,仍然是一个同步等待结果的前台刷盘。
Flush task
真正构造 task 的路径是:
TryScheduleFlushTaskPrepareFlushTaskCaptureFlushSnapshot
其中最核心的是 PrepareFlushTask:
auto BufferManager::PrepareFlushTask(FrameId frame_id, const std::byte *stable_data, bool *was_busy, bool cleaner_owned, BufferTag *tag, uint64_t *dirty_generation) -> Result<bool> {
BufferDescriptor &descriptor = descriptors_[frame_id];
std::unique_lock<std::mutex> descriptor_guard(descriptor.latch);
Result<bool> wait_result = WaitForPendingFlush(&descriptor, &descriptor_guard, stable_data, was_busy);
if (!wait_result.ok()) return wait_result.status();
if (!wait_result.value()) return false;
if (!buffer_descriptor_state::CanFlushResidentFrame(descriptor)) return false;
if (cleaner_owned && buffer_descriptor_state::CleanerMustSkipFlush(descriptor)) {
if (was_busy != nullptr) *was_busy = true;
return false;
}
buffer_descriptor_state::ReserveFlushSlot(&descriptor, tag, dirty_generation);
return true;
}
这一步干了几件关键的事:
- 先等已有的 pending flush 结束
- 检查这个 frame 当前是否真的还是一个可刷盘的 resident dirty page
- 记录本次 flush 针对的 tag 和
dirty_generation - 把
flush_queued标上,等于给这次 flush 占一个槽
这里 dirty_generation 很重要。因为 flush 真正完成时,系统会用它判断,这次刷盘写回的,是不是当前这版脏数据。如果 flush 期间页又被改过,generation 会变化,那么旧 flush 完成后就不能直接把 is_dirty 清掉。
Snapshot 是怎么捕获的
task 构造后,真正被提交给 backend 的不是 frame 的裸指针,而是一份 snapshot:
auto BufferManager::CaptureFlushSnapshot(FrameId frame_id, const std::byte *stable_data) -> std::vector<std::byte> {
std::vector<std::byte> snapshot(page_size_);
if (stable_data != nullptr) {
std::memcpy(snapshot.data(), stable_data, page_size_);
return snapshot;
}
const BufferDescriptor &descriptor = descriptors_[frame_id];
std::shared_lock<std::shared_mutex> content_guard(descriptor.content_latch);
std::memcpy(snapshot.data(), frame_pool_->GetFrameData(frame_id), page_size_);
return snapshot;
}
也就是说:
- 如果调用者已经提供了 stable source,就直接拷贝
- 否则,系统自己拿
content_latch的 shared lock,再从 frame 内存里拷一份 snapshot
所以 flush 写出去的并不是活的 frame 内存,而是一次时刻固定下来的页镜像。因为真正的写请求是异步的,提交后 frame 内容可能继续变化。如果不先 snapshot,异步写出去的内容就可能不一致。
Flush scheduler
构造好 BufferManagerFlushTask 后,task 会进入 BufferManagerFlushScheduler。它内部维护了:
- foreground queue
- background queue
- 多个 worker 线程
Enqueue 只是把 task 放进对应队列:
if (task->cleaner_owned) background_queue_.push_back(task);
else foreground_queue_.push_back(task);
worker 线程在 Run() 里做的事其实很直接:
- 取一个 batch
- 对每个 task 调
disk_backend_->SubmitWrite(task->tag, task->snapshot.data(), page_size_) - 把返回的 request_id 注册给
completion_dispatcher_ - 等 completion
- 完成 task
所以 flush scheduler 本质就是把 flush task 变成真正的异步写请求,并统一等待这些写请求完成。
BufferManager 还会做什么
scheduler 在 task 开始和结束时,都会回调 BufferManager。
开始时调用 BeginFlushTask:
void BufferManager::BeginFlushTask(const std::shared_ptr<BufferManagerFlushTask> &task) {
if (task == nullptr || !task->clear_dirty_on_success) return;
BufferDescriptor &descriptor = descriptors_[task->frame_id];
std::lock_guard<std::mutex> descriptor_guard(descriptor.latch);
descriptor.flush_queued = false;
descriptor.flush_in_flight = true;
descriptor.io_cv.notify_all();
}
这里把 descriptor 从 flush_queued = true 推进到 flush_in_flight = true,说明这次 flush 已经真正开始执行。
完成时调用 FinalizeFlushTask:
void BufferManager::FinalizeFlushTask( const std::shared_ptr<BufferManagerFlushTask> &task, const Status &flush_status) {
if (task->clear_dirty_on_success) {
BufferDescriptor &descriptor = descriptors_[task->frame_id];
bool cleared_dirty = false;
bool should_requeue_cleaner = false;
{
std::lock_guard<std::mutex> descriptor_guard(descriptor.latch);
FinishFlushCompletion(&descriptor, *task, flush_status, &cleared_dirty, &should_requeue_cleaner);
}
if (cleared_dirty) dirty_page_count_.fetch_sub(1, std::memory_order_acq_rel);
if (should_requeue_cleaner) MaybeEnqueueCleanerCandidate(task->frame_id);
else if (cleared_dirty) ResetCleanerCandidate(task->frame_id);
}
if (task->cleaner_owned && cleaner_controller_ != nullptr) cleaner_controller_->OnFlushFinished();
if (flush_status.ok()) observer_->RecordSuccessfulFlush(task->tag);
NotifyCleaner();
}
这一步才是真正的“收尾”:
- 清掉
flush_in_flight - 记录
last_flush_status - 判断能不能清
is_dirty - 必要时减少
dirty_page_count_ - 决定要不要把这个 frame 重新交给 cleaner
- 记录一次 flush telemetry
dirty_generation
为什么 flush 完成后不能总是直接清 dirty,原因就在 dirty_generation。在 FinishFlushCompletion 里,是否能清 dirty,要看:
- flush 是否成功
- frame 现在是不是仍然 resident
- 当前 tag 是否还是 task 对应的 tag
- 当前
dirty_generation是否仍然等于这次 task 捕获时的 generation - 当前页是不是还标记为 dirty
也就是说,如果 flush 期间页又被改过,那么 generation 会变化,旧 flush 完成后就不能把 dirty 清掉。这样才能避免把新修改误当作已经刷盘完成。
小结
所以,一次单页刷盘的完整路径其实是:
FlushBuffer进入前台 flush- 校验 handle 和 stable source
- 预留 flush slot,抓取当前 dirty_generation
- 拷贝一份稳定的 snapshot
- 构造
BufferManagerFlushTask - 交给
FlushScheduler - scheduler 异步提交写请求并等待 completion
BufferManager在完成回调里收尾,决定是否真正清 dirty
从本质上说,这条路径解决的是如何把一个可能仍处于并发访问中的脏页安全地写回磁盘,并保证旧 flush 不会错误覆盖新修改的状态判断。
批量写回与刷盘
FlushAll 就是刚刚单页 flush 路径的自然延伸。并没有发明一套新的刷盘机制,它只是把单页 flush task 的调度与等待扩展到了整个 buffer pool。
它和刚刚那节共用的还是:
TryScheduleFlushTaskFlushSchedulerFinalizeFlushTask
只是触发对象从一个 frame变成了所有 frame。
FlushAll
auto BufferManager::FlushAll() -> Status {
if (!init_status_.ok()) return init_status_;
std::vector<std::shared_ptr<BufferManagerFlushTask>> queued_tasks;
queued_tasks.reserve(pool_size_);
std::vector<FrameId> busy_frames;
busy_frames.reserve(pool_size_);
for (FrameId frame_id = 0; frame_id < pool_size_; ++frame_id) {
bool was_busy = false;
Result<std::shared_ptr<BufferManagerFlushTask>> schedule_result = TryScheduleFlushTask(frame_id, nullptr, &was_busy, false);
if (!schedule_result.ok()) return schedule_result.status();
if (was_busy) {
busy_frames.push_back(frame_id);
continue;
}
if (schedule_result.value() != nullptr) queued_tasks.push_back(std::move(schedule_result.value()));
}
Status wait_status = WaitForScheduledFlushes(queued_tasks);
Status flush_status = FlushBusyFrames(busy_frames);
if (!wait_status.ok()) return wait_status;
return flush_status;
}
先遍历整个 buffer pool
FlushAll 会从 frame_id = 0 一直扫到 pool_size_ - 1。对每个 frame,它都尝试:TryScheduleFlushTask(frame_id, nullptr, &was_busy, false)
stable_data = nullptr 说明这里不是基于某个 handle 的稳定源,而是让系统自己决定怎么 snapshot,was_busy 用来告诉外层这个 frame 当前是不是正忙,cleaner_owned = false 说明这不是后台 cleaner 发起的 flush,而是前台显式 FlushAll。
frame 会被分成三类
遍历每个 frame 后,结果只有三种:
- 这个 frame 不需要刷
- 不是 resident dirty page
- 或当前状态不满足 flush 条件
- 这时
TryScheduleFlushTask会返回空 task,FlushAll 直接跳过。
- 这个 frame 可以立刻调度 flush task
- 这时会拿到一个有效的
BufferManagerFlushTask,被放进queued_tasks后面统一等待。
- 这时会拿到一个有效的
- 这个 frame 当前 busy
- 比如它已经有 pending flush,或者当前状态需要稍后再单独处理。
- 这时
was_busy == true - 它不会立刻进入
queued_tasks,而是先进busy_frames,后面再补处理。
所以 FlushAll 是先对整个 buffer pool 做一次扫描,把 frame 分成“可立即调度”“当前 busy”“无需刷盘”三类。
为什么要分成 queued_tasks 和 busy_frames
queued_tasks 表示:
- 这些 frame 已经成功构造了 flush task
- 可以并行交给 flush scheduler
- 后面只要统一 Wait 即可
busy_frames 表示:
- 这些 frame 当前不适合立即加入这批 task
- 但 FlushAll 也不能直接忽略它们
- 所以后面会单独走
FlushBusyFrames(busy_frames)
这一层设计说明 FlushAll 尽量把当前可并行的先并行发出去,再对忙碌 frame 做补偿式处理。
先等已调度任务,再补刷 busy frame
后半段是:
Status wait_status = WaitForScheduledFlushes(queued_tasks);
Status flush_status = FlushBusyFrames(busy_frames);
if (!wait_status.ok()) return wait_status;
return flush_status;
也就是说:
- 先等那些已经成功进入 scheduler 的 flush task 完成
- 再对之前标记为 busy 的 frame 做补刷
- 如果前半段已经出错,就优先返回前半段错误
- 否则返回 busy frame 那边的结果
所以 FlushAll 先批量调度、再批量等待、再处理遗留 busy frame。
FlushAll 复用单页 flush
FlushAll 复用了单页 flush 的哪一部分?几乎全部。它复用的还是:
TryScheduleFlushTaskPrepareFlushTaskCaptureFlushSnapshotFlushSchedulerFinalizeFlushTask
也就是说:
- 单页 flush 解决某一页如何安全写回
FlushAll解决如何把这套机制扩展到整个池子
FlushAll 在机制上完整复用了单页 flush 的 task 构造、scheduler 提交和 finalize 收尾路径,只是把触发范围扩大到了整个 buffer pool。
总结
FlushAll 是单页刷盘路径在整个 buffer pool 范围上的自然延伸。它并没有重新实现一套新的写回机制,而是遍历所有 frame,尝试为每个 frame 调度 flush task,然后等待这些 task 完成,并对当前 busy 的 frame 做补充处理。
从源码上看,FlushAll 会先扫描整个 buffer pool,并对每个 frame_id 调用 TryScheduleFlushTask(frame_id, nullptr, &was_busy, false)。根据返回结果,每个 frame 会被分成三类:一类是当前不需要刷盘,直接跳过;一类是已经成功构造出 flush task,可以立即加入本轮批量调度;还有一类是当前处于 busy 状态,暂时不能并入本轮 task,需要后续单独处理。
因此,FlushAll 的核心并不是“逐页同步刷盘”,而是先把当前可以并行执行的 flush task 尽量批量发出去,再对遗留的 busy frame 做补偿式处理。其后半段会先等待 queued_tasks 全部完成,再调用 FlushBusyFrames(busy_frames) 处理那些之前来不及并入调度的 frame。
这说明 FlushAll 本质上复用了单页 flush 的全部关键机制,包括 flush slot 预留、snapshot 捕获、flush scheduler 提交以及 flush 完成后的 dirty 状态收尾。它的不同之处,只是把同样的写回逻辑推广到了整个 buffer pool。
后台 cleaner
cleaner 共用的是同一套 flush task、scheduler 和 finalize 机制,区别只在于:
- 谁触发刷盘
- 触发条件是什么
- cleaner 为什么会跳过某些页
Background Cleaner
前面的 FlushBuffer 和 FlushAll 都是显式触发的写回路径,而 background cleaner 则是一条自动触发的后台刷盘路径。它的目标是在脏页数量升高到一定阈值后,主动把一部分适合刷盘的页异步刷回,避免后续前台路径在驱逐时被大量脏页阻塞。
从结构上看,cleaner 并没有重新实现一套新的刷盘逻辑。它依然复用了前面已经讲过的几部分:
- flush task 构造
- flush scheduler 提交
- finalize 阶段的 dirty 状态收尾
它真正新增的是一层后台控制器:BufferManagerCleanerController。
cleaner 机制
cleaner 是否启用由 BufferManagerOptions 控制,其中最关键的是两个水位:
dirty_page_high_watermarkdirty_page_low_watermark
可以把它们理解成一个简单的高水位触发、低水位回落机制,当当前脏页数达到高水位时,cleaner 开始工作,cleaner 不会无限刷下去,而是尽量把脏页数压回到低水位附近。所以 cleaner 的目标不是刷完全部脏页,而是控制脏页规模。
脏页产生后,MarkBufferDirty 在第一次把某页从 clean 变成 dirty 时,会增加 dirty_page_count_,并调用 NotifyCleaner()。此外,flush 完成后、dirty page count 下降后,系统也会再次通知 cleaner,让它重新判断当前是否还需要继续调度后台刷盘。也就是说,cleaner 并不是周期性轮询,而是由脏页状态变化主动驱动的。
后台线程的主体逻辑在 BufferManagerCleanerController::Run() 中。它会等待一个条件成立:dirty_page_count >= dirty_page_high_watermark。一旦达到高水位,cleaner 就会开始计算当前的 flush budget,也就是:当前大概还需要再刷多少页,才能把 dirty page count 压回到低水位附近。如果此时已经有足够多的 cleaner-owned flush 在飞,它会继续等待;如果还没有,就会去 candidate queue 里挑选可以刷的 frame,并通过回调把这些 frame 交给 BufferManager 去调度后台 flush。所以 cleaner 做的事,本质上可以概括为:
- 监控全局脏页数量
- 决定当前是否需要后台写回
- 从候选集合中挑选 frame
- 通过
ScheduleCleanerFlush(frame_id)发起 cleaner-owned flush
candidate queue
cleaner 并不会扫描整个 buffer pool 去“暴力找脏页”,而是维护一套 candidate 机制。只有那些可能适合后台刷盘的页,才会被放进 candidate queue。在 BufferManager 里,像下面这些情况会把 frame 加入 cleaner 候选:
- 某个页被 unpin,且它是 dirty resident page
- flush 完成后,这个页仍然 dirty,且仍适合后台刷盘
- cleaner 启动时,会通过
SeedCleanerCandidates()先扫描一轮,把合适的页加入候选
candidate queue 里不仅有 frame_id,还有 generation。这意味着 cleaner 不只是简单记“这个 frame 曾经是候选”,而是在防止旧候选在状态变化后继续被错误使用。
cleaner 为什么不会乱刷正在用的页
在 PrepareFlushTask(...) 里,如果这次 flush 是 cleaner_owned = true,那么系统还会额外检查当前页是否仍然被 pin 着。如果被 pin,cleaner 就必须跳过,因为后台 cleaner 只负责处理适合在后台写回的页,而不是强行干预活跃的前台访问路径。也就是说:
- foreground flush 更偏调用者明确要求刷
- cleaner flush 更偏系统挑合适时机偷偷提前刷
cleaner 和 flush path 关系
cleaner 虽然是后台自动触发,但一旦选中了某个 frame,后面的路径其实和前面几乎一样:
TryScheduleFlushTaskPrepareFlushTaskCaptureFlushSnapshotEnqueueFlushTaskFlushSchedulerFinalizeFlushTask
所以 cleaner 不是另一套写回系统,而只是前面那套 flush 系统的后台触发器。
小结
background cleaner 本质上解决的是,在前台线程真正需要驱逐或显式刷盘之前,系统能不能提前把一部分脏页以低干扰方式写回,从而减轻后续前台路径的压力。因此,它和 FlushBuffer、FlushAll 的关系并不是替代,而是互补:
- FlushBuffer:显式刷某一页
- FlushAll:显式刷整个池子
- background cleaner:系统根据脏页水位自动做预清理
并发一致性
前面读完请求路径、写回路径和 cleaner 之后,其实会发现 TelePath 的很多复杂度,本质上都来自同一个问题:在并发访问、异步 I/O、后台刷盘和页面驱逐同时发生时,系统如何保证状态不乱。
从当前实现来看,支撑并发一致性的关键不是某一个“大锁”,而是一组相互配合的不变量。
page table 命中不等于页一定可用
BufferTag -> FrameId 只是一个索引关系,真正决定这个页当前能不能被安全访问的,仍然是 BufferDescriptor。因此,命中路径不能只查 page table,还必须继续检查:
state == kResidentis_valid == trueio_in_flight == falsedescriptor.tag == tag
这意味着页表解决的是这个逻辑页现在可能在哪个 frame,而 descriptor 才负责给出这个 frame 当前到底是不是一个可访问的 resident page的最终答案。
pin_count 保证活跃页不会被错误驱逐
一个页只要仍然被 handle 持有,它对应的 frame 就会保持 pin 状态。此时 replacer 不应再把它视为可驱逐对象。只有当 handle Reset() 或析构,最终触发 ReleaseFrame -> UnpinFrame,使 pin_count 回到 0 之后,这个 frame 才会重新变成可驱逐。
因此,pin_count 本质上保护的是:当前仍在被访问的页,不会被后台路径或驱逐路径错误接管。
kLoading + io_in_flight 防止未完成装载的页被提前暴露
当一个 miss owner 已经预留好 frame,并把 descriptor 推进到 kLoading 后,这个页在 page table 中已经有映射,但这时它还不能被当作 resident page 返回。只有真正完成读盘并执行 CompleteLoadedFrame(frame_id) 后,descriptor 才会变成 kResident。
因此,kLoading 和 io_in_flight 这组状态一起保证:页的逻辑安装和页的物理可用之间可以存在中间态,但这个中间态不会被误当作正常 resident page。
dirty_generation 防止旧 flush 错误清掉新修改
刷盘路径里最关键的一点是:flush 完成后不能无脑把 is_dirty 清成 false。因为在 flush 进行期间,这个页可能又被新的写请求修改了。
因此系统在构造 flush task 时会记录当前的 dirty_generation,而在 flush 完成时,只有当:
- 当前页仍然是同一个 tag
- 当前 generation 仍然等于 task 记录的 generation
- 当前页仍然是 dirty resident page
这些条件都成立时,才允许清 dirty。
所以 dirty_generation 实际上是在保证:旧的刷盘结果不会错误覆盖新的脏状态判断。
content_latch 保证页内容访问和 snapshot 捕获的一致性
BufferHandle::data() 与 mutable_data() 并不只是返回一个指针,它们还负责建立对页面内容的受控访问:只读访问持有 shared lock,可写访问持有 unique lock。写回路径在没有 stable source 时,也会通过 content_latch 获取 shared lock 后再抓取 snapshot。
因此,页内容的一致性靠 content_latch 来保证:读取、写入和 flush snapshot 捕获都发生在受控的内容访问协议之下。
cleaner 只是后台触发器,不拥有额外的特权
background cleaner 会主动调度 flush,但它并不能绕过前面所有一致性约束。对于仍被 pin 的页、当前已有 flush 在飞的页,或者状态已经变化的旧 candidate,cleaner 都必须跳过。
这说明 cleaner 虽然是后台组件,但它并不拥有强制刷盘的额外特权,而只是复用了同一套 flush task 和状态检查逻辑。
小结
所以从整体上看,TelePath 的并发一致性通过:
- page table 与 descriptor 的双重校验
- pin/unpin 生命周期
- loading / resident 状态机
- dirty generation
- content latch
- cleaner 与 foreground flush 的统一状态约束
共同维持的。
换句话说,这个系统真正难的地方,不是在怎么读页、怎么写页,而是在这些路径并发交叠时,如何保证每个状态转换都仍然成立。